My research focuses on Learning Representations as the foundation of next-generation AI, integrating mathematical optimization, symbolic reasoning, and compositional world models. I focus on Autonomy-Driven Interpretability to enable auditable and controllable large-scale models. Through AI for Social Good, I aim to build AI agents that can reason, adapt, and align with human values.
Currently, I serve as (1) a Senior Research Scientist (Head of AI) at MARSAIL, (2) a C2F Postdoctoral Fellow at Chulalongkorn University, (3) an Adjunct Professor at Khon Kaen University, and founder of PBYAIL, developing scalable AI on geo-data to reduce disaster impact and support planetary resilience. Driven by a passion for research, I received my Ph.D. in Computer Engineering from Chulalongkorn University.
With great honor, I will be joining the Government Savings Bank (GSB) as Deputy Director of AI, where I aim to lead strategic AI innovation and advance trustworthy, scalable, and interpretable systems for Thailand’s national banking ecosystem.
Detailed summaries of my academic, industry, and teaching experience can be found in my CV or IEEE Biography, and get a glimpse into my personal life on my blog and tumblr. By the way, feel free to vibe to my music on SoundCloud and my UTMB World.
Thai name: ธีรพงศ์ ปานบุญยืน, aka Kao Panboonyuen, or just Kao (เก้า).
- Applied Earth Observations
- Geoscience and Remote Sensing
- Computer Vision
- Semantic Distillation
- Human-AI Interaction
- Learning Representations
-
PostDoc Fellow in AI, 2027
Chulalongkorn University
-
PhD in Computer Engineering, 2020
Chulalongkorn University
-
MEng in Computer Engineering, 2017
Chulalongkorn University
-
BEng in Computer Engineering, 2015
KMUTNB (Top 1% in University Mathematics)
-
Pre-Engineering School (PET21), 2012
KMUTNB (Senior High School, 10th - 12th Grade)
Selected Awards
- H.M. the King Bhumibhol Adulyadej’s 72nd Birthday Anniversary Scholarship (Master) (Recipients)
- The 100th Anniversary Chulalongkorn University Fund for Doctoral Scholarship (Ph.D.) (Recipients)
- The 90th Anniversary of Chulalongkorn University Scholarship (Ph.D.)
- Postdoctoral Grant, Ratchadapisek Research Fund (RRF) (Chulalongkorn University) (Postdoc, 2021-2025) (Recipients)
- Postdoctoral Research Grant, Second Century Fund (C2F) (Chulalongkorn University) (Postdoc, 2025-2026) (Recipients) (C2F Certificate)
- Postdoctoral Research Grant, Second Century Fund (C2F) (Chulalongkorn University) (Postdoc, 2026-2027) (Recipients) (Grant No. C2F PD-2120260123)
- Top 1% Score in University Differential Calculus and Engineering Mathematics
- 2016 EBA Disaster Management Fieldwork. International fieldwork on big data applications, hosted by Keio University, Japan (EBA)
- 2017 Best Student Paper Award in International Conference on Computing and Information Technology (IC2IT)
- 2019 Best Young Researcher Paper Award in First International Conference on Smart Technology & Urban Development (STUD)
- 2020 Ph.D. Defense Pass. Proudly completed my doctoral journey, advancing the frontier of geospatial AI with FusionNetGeoLabel (Ph.D. Defense Slides)
- 2022 Bangkok Marathon 42.195K Finisher with successfully completed a full marathon run (42.195 kilometers) (Bangkok Marathon)
- 2023 AI Research Featured in Techsauce News. Grateful to be spotlighted for pushing the frontier of AI innovation. (Techsauce).
- 2024 IRONMAN 70.3 Finisher with successfully completed a challenging triathlon consisting of a 1.9K swim, 90K bike ride, and 21.1K run (IM70.3)
- 2024 Laguna Phuket Triathlon Finisher with successfully completed a challenging triathlon consisting of a 1.8K swim, 55K bike ride, and 12K run (LPT)
- 2024 Distinguished Reviewer for the Bronze Level of IEEE Transactions on Medical Imaging (Certificate)
- 2025 Chombueng Marathon 42.195K Finisher with successfully completed a full marathon run (42.195 kilometers) (Chombueng Marathon)
- 2025 UTMB Word Series INTHANON20 Finisher with successfully completed a 20K trail run in the UTMB World Series (UTMB Chiang Mai)
- 2025 My 25th Blood Donation marks a milestone of compassion, generosity, and giving back to society, helping fellow humans (Thai Red Cross Society).
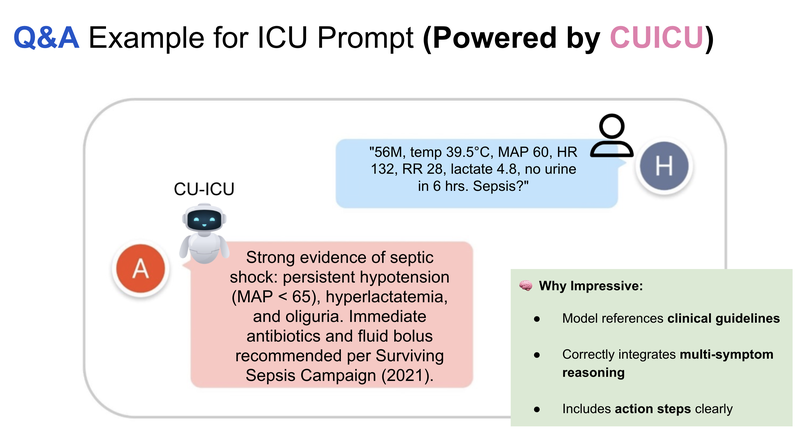
- 2025 Oral Presentation – Selected Among Top 12.5% Abstracts at the 14th Critical Care Conference, organized by the Thai Society of Critical Care Medicine (TSCCM)
- 2025 Global Young Scientists Summit (GYSS) Scholarship from Her Royal Highness Princess Maha Chakri Sirindhorn (GYSS)
- 2026 AutoTech Aftermarket Summit 2026 invited as a speaker to share insights on automotive AI in my role as Head of AI at MARSAIL (AutoTech Blog)
- 2026 ASEAN Young Scientists Connect (AYSC) invited to participate in AYSC 2026, a platform for young researchers across ASEAN fostering collaboration (AYSC)
- 2026 AOGS (Asia Oceania Geosciences Society) invited to present my KAO research in Fukuoka Japan (AOGS Invitation Letter)
Reviewer for International Journals/Conferences:
- Invited Reviewer of Pattern Recognition (Elsevier)
- Invited Reviewer of Neurocomputing (Elsevier)
- Invited Reviewer of Transactions on Knowledge Discovery from Data (ACM)
- Invited Reviewer of Computer Vision and Image Understanding (Elsevier)
- Invited Reviewer of Computers and Geosciences (Elsevier)
- Invited Reviewer of Neural Networks (Elsevier) (Certificate)
- Invited Reviewer of Remote Sensing (MDPI)
- Invited Reviewer of Artificial Intelligence Review (Nature Portfolio)
- Invited Reviewer of Scientific Reports (Nature Portfolio) (Certificate)
- Invited Reviewer of GIScience & Remote Sensing (Taylor & Francis)
- Invited Reviewer of European Journal of Remote Sensing (Taylor & Francis)
- Invited Reviewer of International Journal of Remote Sensing (Taylor & Francis)
- Invited Reviewer of Remote Sensing Applications: Society and Environment (Elsevier)
- Invited Reviewer of IEEE Transactions on Artificial Intelligence (IEEE)
- Invited Reviewer of IEEE Transactions on Big Data (IEEE)
- Invited Reviewer of IEEE Transactions on Image Processing (IEEE)
- Invited Reviewer of IEEE Transactions on Medical Imaging (IEEE) (Certificate)
- Invited Reviewer of IEEE Transactions on Mobile Computing (IEEE)
- Invited Reviewer of IEEE Transactions on Geoscience and Remote Sensing (IEEE)
- Invited Reviewer of Pattern Analysis and Machine Intelligence (TPAMI) (IEEE)
- Recognized as an IOP Trusted Reviewer (IOP Publishing): 2024, 2025
- More reviews can be found under my WoS ID AAO-4985-2020.
- More certificates of reviewers can be found at my GitHub Repository.
Additional Certifications in Research Ethics:
- My certificate in GCP (Good Clinical Practice) – Ethics in Human Research is available in my GCP Certificate (English) and my GCP Certificate (Thai).
Editor for International Journals/Conferences:
-
I serve as an Editorial Board Member for Discover Artificial Intelligence (Springer). My editorial training certificates are available here:
- Welcome Course for Inclusive Journals: Certificate
- Determining Suitability for Peer Review: Certificate
- Identifying and Securing Potential Candidates: Certificate
- Making Editorial Decisions and Evaluating Peer Reviewer Reports: Certificate
Selected Press
- The Leader Asia: Dr. Teerapong and his team introduced their advanced AI for car damage detection at ICIAP 2023 in Udine, setting new accuracy standards with their innovative MARS model.
- Techsauce: Highlighted their AI technology for automatic car damage assessment, earning recognition for excellence at ICIAP 2023 in Italy.
- LINE TODAY: Showcased the MARS model at ICIAP 2023, noted for its high accuracy and setting new global standards in car damage detection.
- Moneychat: Reported the award-winning innovation in AI for car damage estimation presented at ICIAP 2023.
- Kaohoon: Celebrated the award-winning success of MARSAIL at ICIAP 2023.
- Mitistock: Introduced the MARS model, featuring advanced self-attention mechanisms for vehicle damage assessment in Thailand.
- The Story Thailand: Presented cutting-edge AI techniques in car wound detection, achieving high accuracy and setting international benchmarks.
- Media of Thailand: Unveiled the MARS model at ICIAP 2023, recognized globally for its precision in car damage detection.
- Thailand Insurance News: Featured Dr. Teerapong’s MARS model at ICIAP 2023 for its groundbreaking accuracy in car damage detection.
- WealthPlusToday: Dr. Teerapong’s MARSAIL wowed ICIAP 2023 in Italy, clinching an excellence award for next-gen car damage detection.
- Chulalongkorn University: Published a study on semantic road segmentation using deep convolutional neural networks.
- Chula Engineering News: Featured Dr. Teerapong’s participation in the Global Young Scientists Summit (GYSS) 2025, highlighting academic leadership and global collaboration.
- Thaivivat Insurance: Announced Dr. Teerapong’s research recognition at UAMC 2025, emphasizing advancements in AI for urban analytics and mobility challenges.
Featured Publications
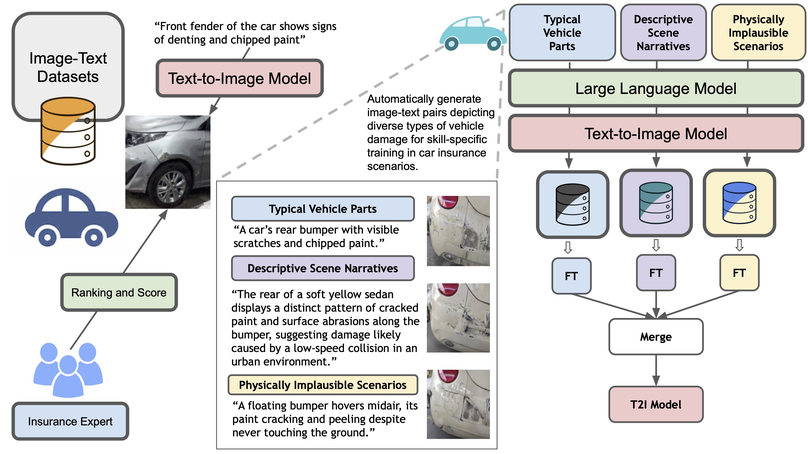
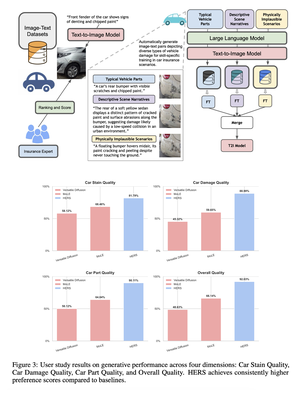
HERS presents a domain-adaptive diffusion framework for controllable, realistic, and trustworthy vehicle damage synthesis. The method decomposes complex damage generation into a set of risk-specific expert modules, each specializing in a particular damage type such as dents, scratches, broken lights, or cracked paint, and trained using self-supervised image–text pairs without manual annotation. These experts are later integrated into a unified diffusion model that balances specialization with generalization, enabling precise control over damage attributes while maintaining visual coherence. Extensive experiments across multiple diffusion backbones demonstrate consistent improvements in text–image alignment and human preference over standard fine-tuning baselines. Beyond visual fidelity, HERS highlights broader implications for auditability, fraud prevention, and the responsible deployment of generative models in high-stakes domains, underscoring the need for trustworthy and risk-aware diffusion systems in applications such as automated insurance assessment.


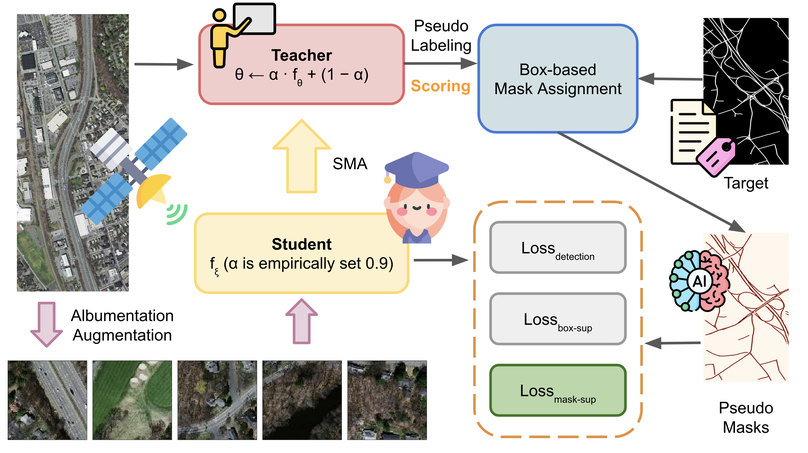
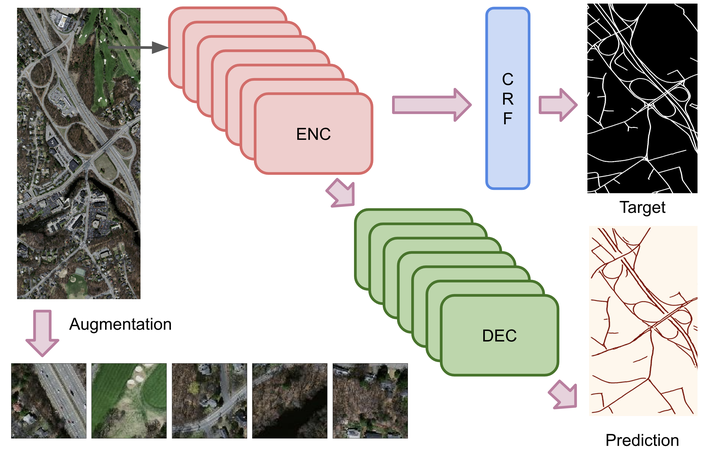
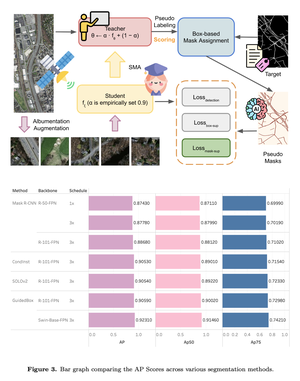
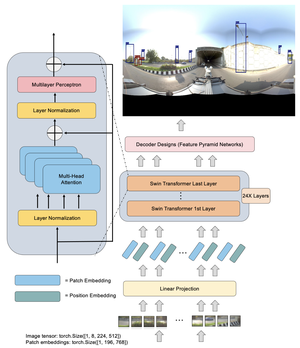
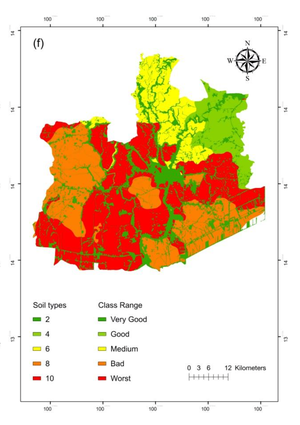
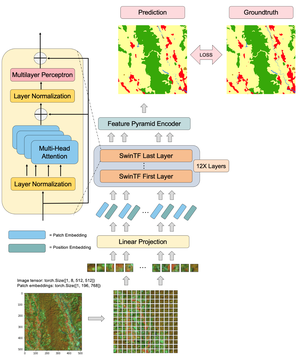
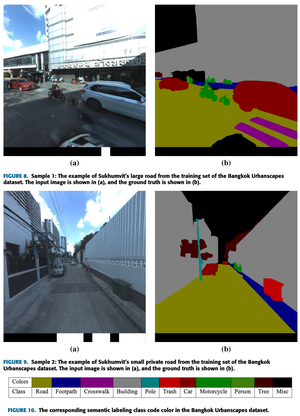
Road segmentation in remote sensing is crucial for applications like urban planning, traffic monitoring, and autonomous driving. Labeling objects via pixel-wise segmentation is challenging compared to bounding boxes. Existing weakly supervised segmentation methods often rely on heuristic bounding box priors, but we propose that box-supervised techniques can yield better results. Introducing GuidedBox, an end-to-end framework for weakly supervised instance segmentation. GuidedBox uses a teacher model to generate high-quality pseudo-masks and employs a confidence scoring mechanism to filter out noisy masks. We also introduce a noise-aware pixel loss and affinity loss to optimize the student model with pseudo-masks. Our extensive experiments show that GuidedBox outperforms state-of-the-art methods like SOLOv2, CondInst, and Mask R-CNN on the Massachusetts Roads Dataset, achieving an AP50 score of 0.9231. It also shows strong performance on SpaceNet and DeepGlobe datasets, proving its versatility in remote sensing applications. Code has been made available at https://github.com/kaopanboonyuen/GuidedBox.


Satellite image inpainting is a critical task in remote sensing, requiring accurate restoration of missing or occluded regions for reliable image analysis. In this paper, we present SatDiff, an advanced inpainting framework based on diffusion models, specifically designed to tackle the challenges posed by very high-resolution (VHR) satellite datasets such as DeepGlobe and the Massachusetts Roads Dataset. Building on insights from our previous work, SatInPaint, we enhance the approach to achieve even higher recall and overall performance. SatDiff introduces a novel Latent Space Conditioning technique that leverages a compact latent space for efficient and precise inpainting. Additionally, we integrate Explicit Propagation into the diffusion process, enabling forward-backward fusion for improved stability and accuracy. Inspired by encoder-decoder architectures like the Segment Anything Model (SAM), SatDiff is seamlessly adaptable to diverse satellite imagery scenarios. By balancing the efficiency of preconditioned models with the flexibility of postconditioned approaches, SatDiff establishes a new benchmark in VHR satellite datasets, offering a scalable and high-performance solution for satellite image restoration. The code for SatDiff is publicly available at https://github.com/kaopanboonyuen/SatDiff.
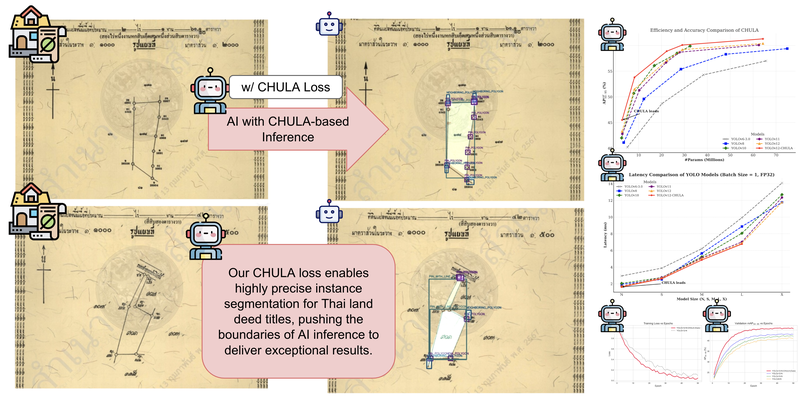
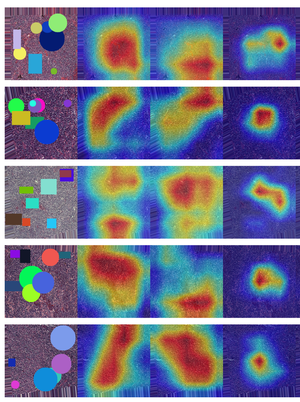
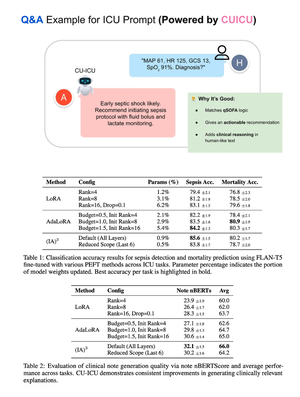
Accurately segmenting land boundaries from Thai land title deeds is crucial for reliable land management and legal processes, but remains challenging due to low-quality scans, diverse layouts, and complex overlapping elements in documents. Existing methods often struggle with these difficulties, resulting in imprecise delineations that can cause disputes or inefficiencies. To address these issues, we propose CHULA, a novel Custom Heuristic Uncertainty-guided Loss tailored specifically for robust land title deed segmentation. CHULA uniquely combines domain-specific heuristic priors with uncertainty modeling in a unified loss function that effectively guides the model to focus on clearer regions while refining boundaries and suppressing noisy areas. Evaluated on a carefully curated Thai Land Title Deed Dataset, CHULA achieves an impressive 92.4% accuracy, significantly surpassing standard segmentation baselines. Our results highlight the promise of integrating uncertainty and heuristic knowledge to enhance segmentation accuracy in complex, real-world documents. The code is publicly available at https://github.com/kaopanboonyuen/CHULA.
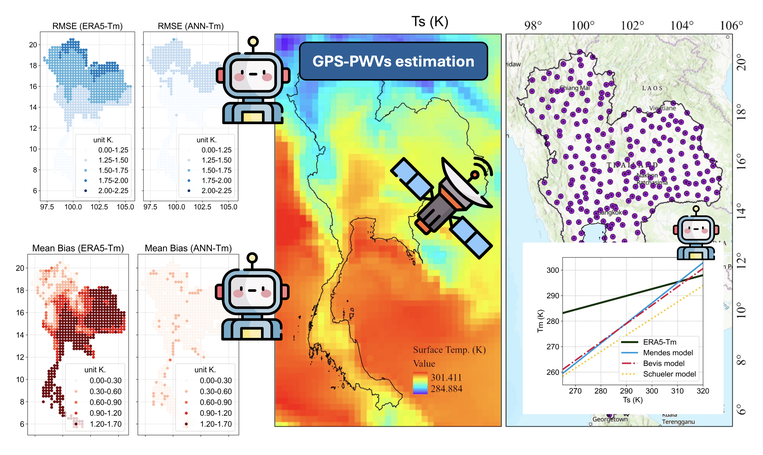

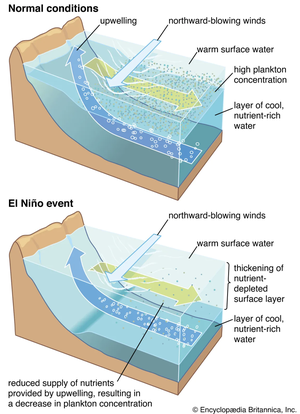
Forecasting sea surface currents is essential for applications such as maritime navigation, environmental monitoring, and climate analysis, particularly in regions like the Gulf of Thailand and the Andaman Sea. This paper introduces SEA-ViT, an advanced deep learning model that integrates Vision Transformer (ViT) with bidirectional Gated Recurrent Units (GRUs) to capture spatio-temporal covariance for predicting sea surface currents (U, V) using high-frequency radar (HF) data. The name SEA-ViT is derived from Sea Surface Currents Forecasting using Vision Transformer, highlighting the model’s emphasis on ocean dynamics and its use of the ViT architecture to enhance forecasting capabilities. SEA-ViT is designed to unravel complex dependencies by leveraging a rich dataset spanning over 30 years and incorporating ENSO indices (El Niño, La Niña, and neutral phases) to address the intricate relationship between geographic coordinates and climatic variations. This development enhances the predictive capabilities for sea surface currents, supporting the efforts of the Geo-Informatics and Space Technology Development Agency (GISTDA) in Thailand’s maritime regions. The code and pretrained models are available at https://github.com/kaopanboonyuen/gistda-ai-sea-surface-currents.
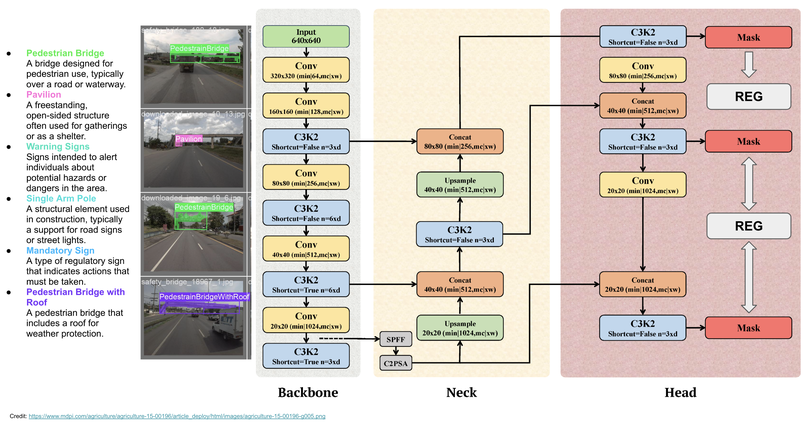
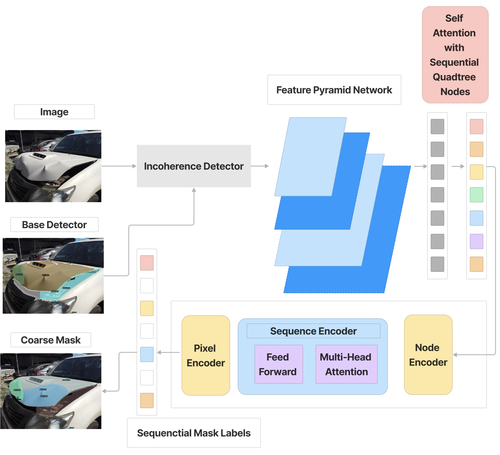
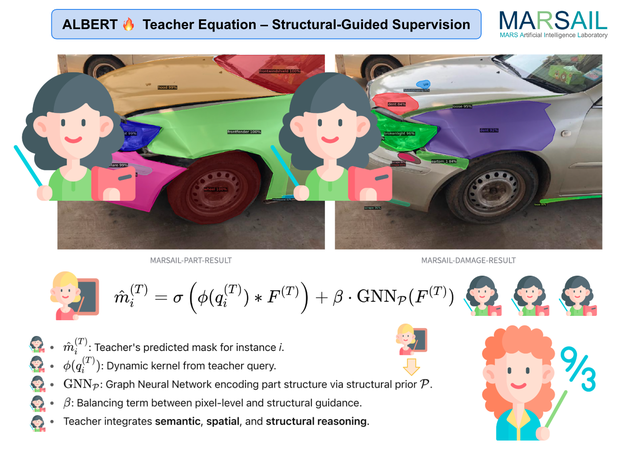
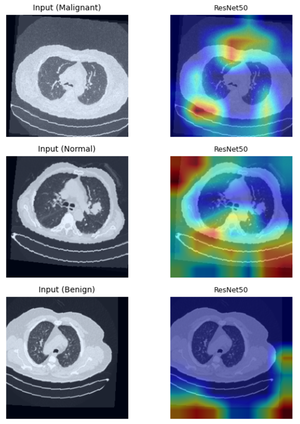
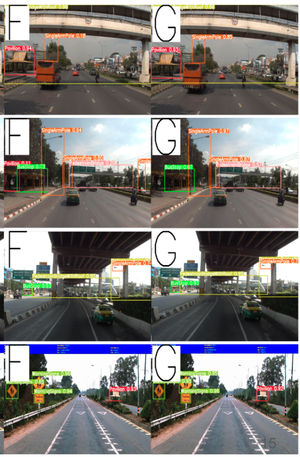
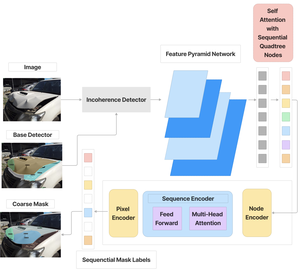
Evaluating car damages is crucial for the car insurance industry, but current deep learning networks fall short in accuracy due to inadequacies in handling car damage images and producing fine segmentation masks. This paper introduces MARS (Mask Attention Refinement with Sequential quadtree nodes) for instance segmentation of car damages. MARS employs self-attention mechanisms to capture global dependencies within sequential quadtree nodes and a quadtree transformer to recalibrate channel weights, resulting in highly accurate instance masks. Extensive experiments show that MARS significantly outperforms state-of-the-art methods like Mask R-CNN, PointRend, and Mask Transfiner on three popular benchmarks, achieving a +1.3 maskAP improvement with the R50-FPN backbone and +2.3 maskAP with the R101-FPN backbone on the Thai car-damage dataset. Demos are available at https://github.com/kaopanboonyuen/MARS.
Publications
To find relevant content, try searching publications, filtering using the buttons below, or exploring popular topics. A * denotes equal contribution.
*







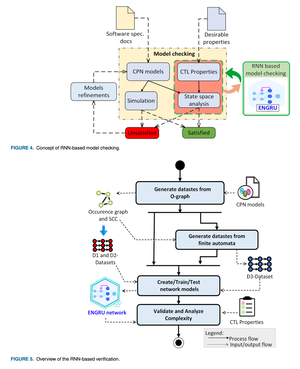



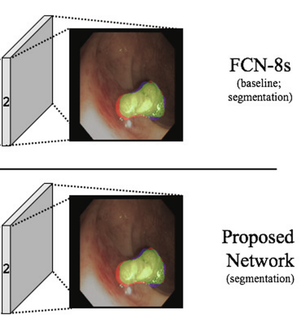


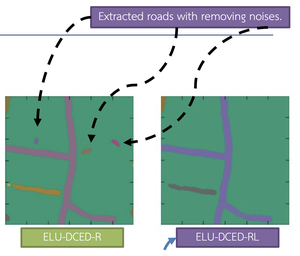
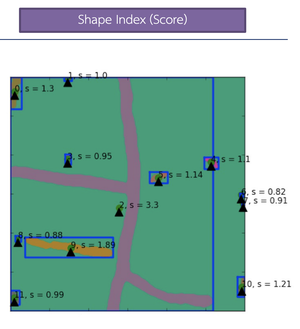

Featured Talks








Research Communities
-
Visiting Faculty - College of Computing, Khon Kaen University
-
June 2023 - Present
-
Teach courses:
- SC310005 Artificial Intelligence and Machine Learning Application: Introduction to AI and ML concepts and their applications.
- CP020002 Smart Process Management: Techniques for optimizing and automating business processes.
- SC320002 Business Intelligence: Methods for data analysis and decision-making in business contexts.
- CP020001 Introduction to Computers and Programming: Basics of computer systems and introductory programming skills.
- DE200001 Fundamentals of Data Engineering: Introduction to data engineering concepts and fundamental tools for beginners.
-
Ministerial Order on the Appointment of Academic Staff (Order 5907-2566)
-
Invitation Letter for a Special Lecturer Position (Order อว 660101.26/9304)
-
Invitation Letter for a Special Lecturer Position (Order อว 660101.26/24844)
-
Invitation Letter for a Special Lecturer Position (Order อว 660101.26/13320)
-
Order on the Appointment as University Permanent Staff (Order 10634/2568)
- New Faculty Orientation on Zoom: Online orientation session welcoming newly appointed faculty members.
- Digital University Staff ID on iKKU: Official online staff identification card accessible through the iKKU system.
-
-
Senior Research Scientist (Head of AI) - MARS (Motor AI Recognition Solution)
- January 2022 - Present
- Led AI Research & Development across MARS.
- MARS AI Research Portfolio
- Foundations and Architectures of AI for Motor Insurance (Textbook)
- Official HR Certification – Appointment as Head of AI at MARS
-
Guest Lecturer and AI Committee Member
-
Smart Detective: AI in Solving Mysteries (NAC2025)
- Delivered an interactive workshop on deep learning and computer vision, introducing how Vision Transformers achieve breakthroughs in image recognition.
- Guided hands‑on model building—training an AI system to detect Waldo.
-
- Delivered keynote on “Mathematical Foundations of Vision Transformers in Car Insurance AI.”
- Poster: UAMC2025
-
AI Instructor - Department of Lands, Thailand (2025)
- Taught Large Language Models (LLMs) using land title deed data and demonstrated AI-driven automation for creating land deeds.
- Code and Lecture Slides
-
AI Instructor - Office of the Cane and Sugar Board (2025)
- Leveraged Vision Transformer model for accurate sugarcane area classification and boundary detection from satellite images.
-
NSTDA One Day Camp at Sirindhorn Science Home (2024)
- Talking about career opportunities and becoming a research scientist in AI as part of the GYSS2025 scholarship program.
- Full Blog and Slide: Career Paths for AI Research Scientists
-
2108421 Modern Integrated Survey Technology (MIST) - Chulalongkorn University
- Guided students in applying Machine Learning to survey engineering.
-
CP411701 AI Inspiration Course - Khon Kaen University
- Delivered a lecture on “Generative AI: Current Trends and Practical Applications” at the College of Computing, Khon Kaen University.
- Slide: Generative AI
-
The 7th KVIS Invitational Science Fair
- Served as a committee member for the AI project at Kamnoetvidya Science Academy, Rayong, Thailand (29 January - 2 February 2024).
-
Industrial Advisory Board (IAB) - ECE KMUTNB
- Contributed to curriculum assessment and provided comments for the Department of Electrical and Computer Engineering (ECE).
-
AI and ML Instructor - Nomklao Kunnathi Demonstration School
- Taught AI and ML under the Design Graphics Science and Technology Learning Group for high school students (Grade 10) in the Science and Mathematics Curriculum Plan.
-
Deep Learning Instructor - Thammasat University
- Conducted training on satellite data processing and interpretation for advanced military and disaster missions at the Faculty of Liberal Arts.
-
Senior Project Advisor - Thammasat University
- Advised students on senior projects in the Department of Geography, Faculty of Liberal Arts.
-
AI Instructor - Department of Lands, Thailand
- Taught AI using land title deed data. Code and Lecture Slides
-
- Public AI/LLM models that I fine-tuned for the research community.
-