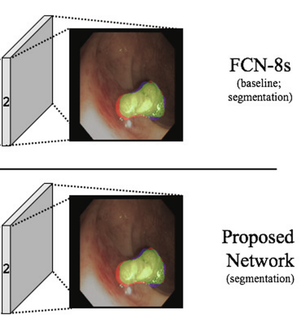
1
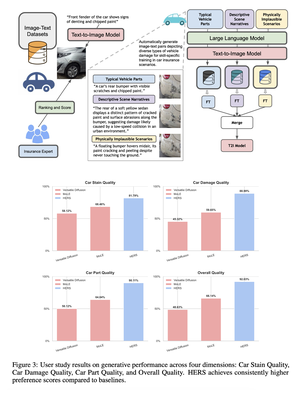
HERS: Hidden-Pattern Expert Learning for Risk-Specific Vehicle Damage Adaptation in Diffusion Models
HERS presents a domain-adaptive diffusion framework for controllable, realistic, and trustworthy vehicle damage synthesis. The method decomposes complex damage generation into a set of risk-specific expert modules, each specializing in a particular damage type such as dents, scratches, broken lights, or cracked paint, and trained using self-supervised image–text pairs without manual annotation. These experts are later integrated into a unified diffusion model that balances specialization with generalization, enabling precise control over damage attributes while maintaining visual coherence. Extensive experiments across multiple diffusion backbones demonstrate consistent improvements in text–image alignment and human preference over standard fine-tuning baselines. Beyond visual fidelity, HERS highlights broader implications for auditability, fraud prevention, and the responsible deployment of generative models in high-stakes domains, underscoring the need for trustworthy and risk-aware diffusion systems in applications such as automated insurance assessment.

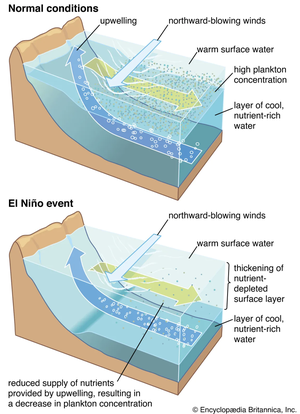
Forecasting sea surface currents is essential for applications such as maritime navigation, environmental monitoring, and climate analysis, particularly in regions like the Gulf of Thailand and the Andaman Sea. This paper introduces SEA-ViT, an advanced deep learning model that integrates Vision Transformer (ViT) with bidirectional Gated Recurrent Units (GRUs) to capture spatio-temporal covariance for predicting sea surface currents (U, V) using high-frequency radar (HF) data. The name SEA-ViT is derived from Sea Surface Currents Forecasting using Vision Transformer, highlighting the model’s emphasis on ocean dynamics and its use of the ViT architecture to enhance forecasting capabilities. SEA-ViT is designed to unravel complex dependencies by leveraging a rich dataset spanning over 30 years and incorporating ENSO indices (El Niño, La Niña, and neutral phases) to address the intricate relationship between geographic coordinates and climatic variations. This development enhances the predictive capabilities for sea surface currents, supporting the efforts of the Geo-Informatics and Space Technology Development Agency (GISTDA) in Thailand’s maritime regions. The code and pretrained models are available at https://github.com/kaopanboonyuen/gistda-ai-sea-surface-currents.
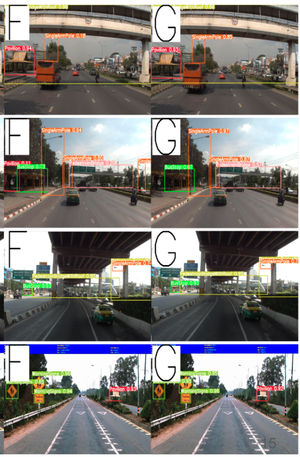
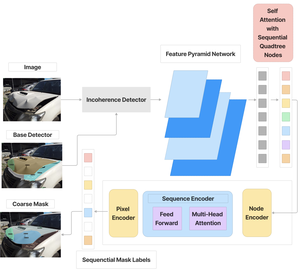
Evaluating car damages is crucial for the car insurance industry, but current deep learning networks fall short in accuracy due to inadequacies in handling car damage images and producing fine segmentation masks. This paper introduces MARS (Mask Attention Refinement with Sequential quadtree nodes) for instance segmentation of car damages. MARS employs self-attention mechanisms to capture global dependencies within sequential quadtree nodes and a quadtree transformer to recalibrate channel weights, resulting in highly accurate instance masks. Extensive experiments show that MARS significantly outperforms state-of-the-art methods like Mask R-CNN, PointRend, and Mask Transfiner on three popular benchmarks, achieving a +1.3 maskAP improvement with the R50-FPN backbone and +2.3 maskAP with the R101-FPN backbone on the Thai car-damage dataset. Demos are available at https://github.com/kaopanboonyuen/MARS.
In today’s world, urban design and sustainable development are crucial for megacities, impacting residents’ wellbeing. Quality of Life (QOL) is a key performance indicator (KPI) used to measure the effectiveness of city planning. Traditionally, QOL is assessed through costly and time-consuming surveys, but our AI-based approach offers a more efficient solution. Using Bangkok as a case study, we apply deep convolutional neural networks (DCNNs) for semantic segmentation and object detection to gather relevant image data. Then, we use linear regression to infer QOL scores. Our method, tested with state-of-the-art models and public datasets, proves to be a practical alternative for QOL assessment, with implementation codes and datasets available at https://kaopanboonyuen.github.io/bkkurbanscapes.