CAREF: Calibration-Aware Regularization for Explanation Faithfulness Without Rationale Supervision
Abstract
Large language models can generate natural language explanations that appear convincing yet often fail to faithfully reflect the internal reasoning process underlying model predictions. Existing approaches for improving explanation faithfulness typically rely on rationale supervision, token-level annotations, or computationally expensive full-model fine-tuning. We propose CAREF, a Calibration-Aware Regularization framework for Explanation Faithfulness that jointly optimizes predictive accuracy and explanation quality through a unified calibration-aware objective. At the core of CAREF lies the Sparsity-Calibrated Entropic Divergence (SCED) loss, which integrates entropy-based calibration and adaptive token-level sparsity within a single differentiable regularization term without requiring rationale supervision. By encouraging predictions to rely on compact and decision-relevant token subsets, CAREF improves the alignment between generated explanations and model decisions. Extensive experiments on four Natural Language Explanation benchmarks (COS-E, ECQA, ComVE, and e-SNLI) demonstrate that CAREF consistently improves both predictive performance and explanation faithfulness. The CAREF-AQ variant achieves the best average accuracy and explanation alignment while updating only 6.43% of model parameters, outperforming strong PEFT baselines including LoRA and AdaLoRA. To our knowledge, CAREF is the first framework to unify entropy calibration and adaptive sparsity regularization within a single objective for explanation-faithful language model fine-tuning.
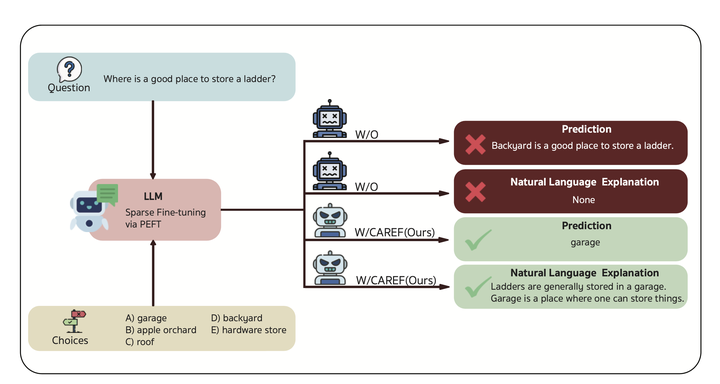
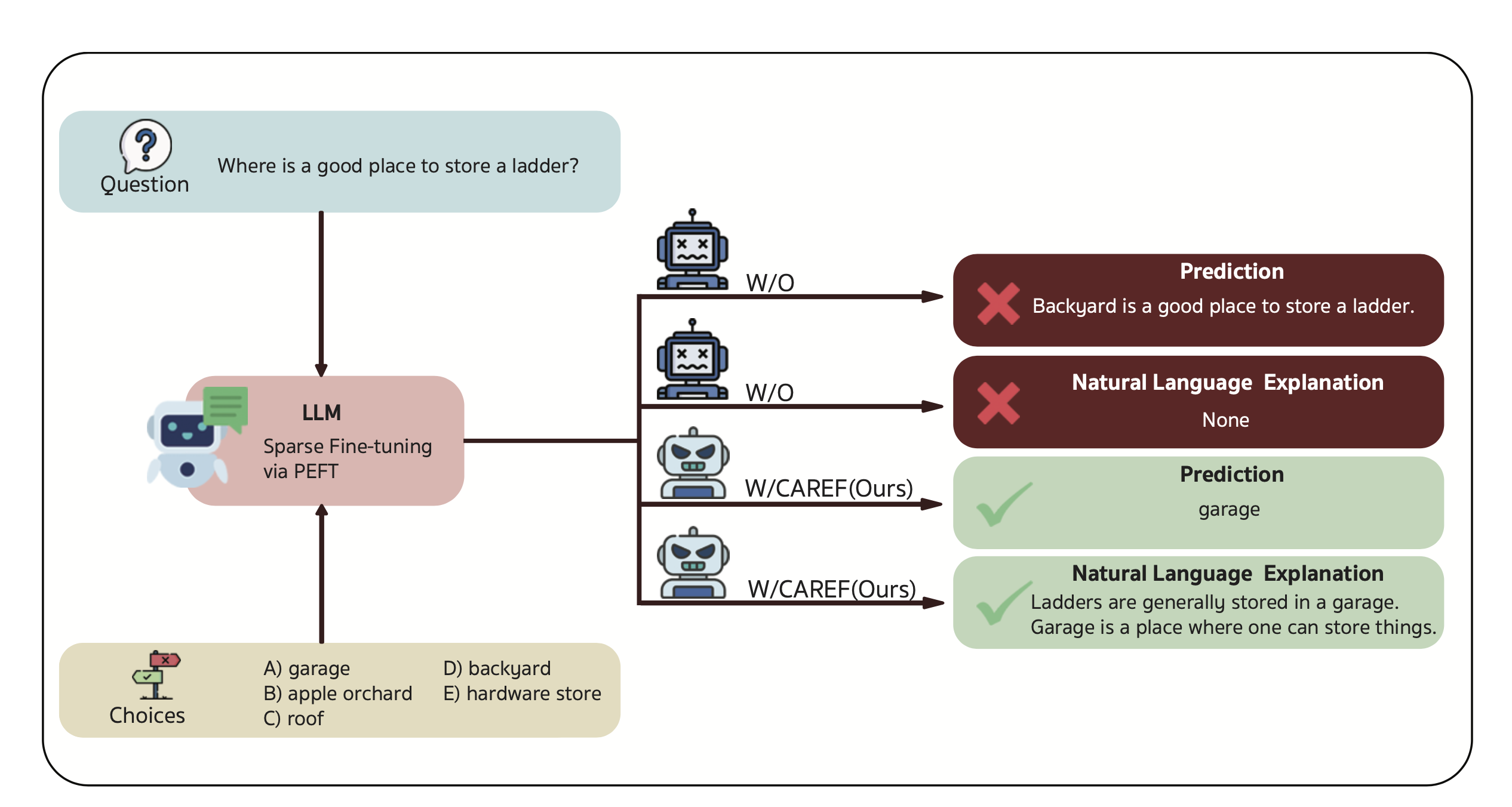
CAREF (Calibration-Aware Regularization for Explanation Faithfulness) addresses a fundamental challenge in explainable language modeling: ensuring that generated explanations genuinely reflect the reasoning process that produces model predictions. While modern large language models are capable of generating fluent and persuasive explanations, these explanations are frequently plausible rather than faithful, leading to a disconnect between what the model says and what actually drives its decisions.
CAREF introduces a unified calibration-aware regularization framework that improves explanation faithfulness without requiring rationale supervision. The proposed Sparsity-Calibrated Entropic Divergence (SCED) objective combines entropy-based calibration and adaptive token-level sparsity within a single differentiable loss, encouraging models to focus on compact and decision-relevant token subsets while suppressing diffuse and potentially misleading probability distributions.
The central insight behind CAREF is that faithful explanations emerge when predictions are grounded in a stable and causally relevant subset of tokens rather than broad or overconfident distributions. Unlike rationale-supervised approaches that require expensive token-level annotations, CAREF operates solely through distributional regularization and standard task supervision. This makes the framework practical, scalable, and applicable to a wide range of natural language explanation tasks.
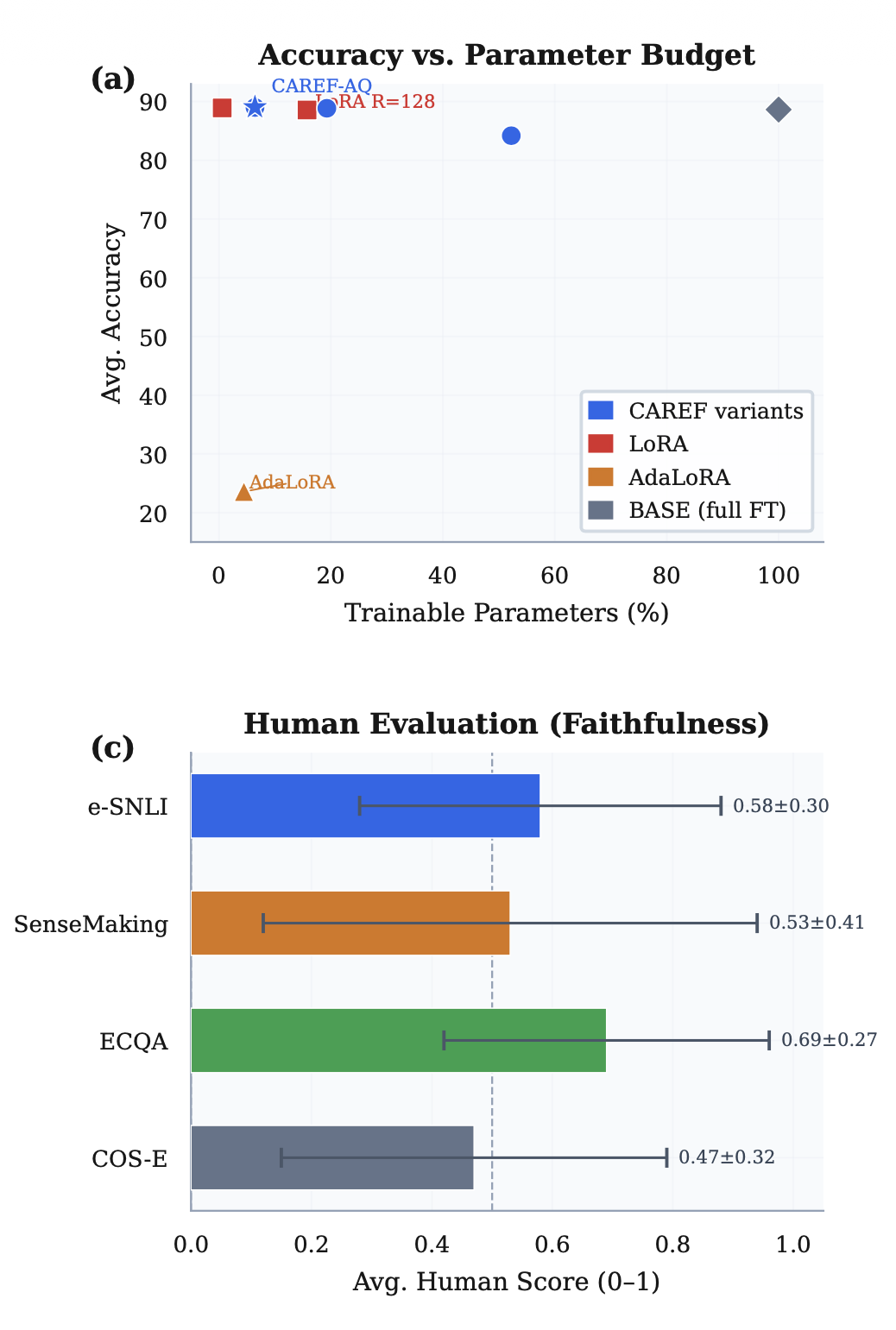
A key advantage of CAREF is its compatibility with parameter-efficient fine-tuning methods. Because the SCED objective acts directly on model output distributions, it can be integrated seamlessly with existing PEFT techniques such as LoRA, adapters, and attention-only tuning without modifying model architectures. Experimental results across COS-E, ECQA, ComVE, and e-SNLI demonstrate consistent improvements in both predictive accuracy and explanation quality over strong baseline methods.
The CAREF-AQ variant further shows that explanation-faithful adaptation can be achieved with remarkable efficiency. By updating only decoder attention query projections—representing just 6.43% of model parameters—CAREF-AQ surpasses both full fine-tuning and widely adopted PEFT baselines including LoRA and AdaLoRA. These findings suggest that calibration-aware sparsity regularization provides an effective mechanism for aligning model explanations with decision-making processes while maintaining computational efficiency.
Beyond empirical gains, CAREF highlights a broader direction for trustworthy language model development. By directly shaping predictive distributions through unified entropy calibration and adaptive sparsity control, CAREF offers a principled framework for improving explanation faithfulness without external rationale annotations. This establishes a scalable pathway toward more interpretable, reliable, and transparent language models for real-world deployment.
Teerapong Panboonyuen
My research focuses on leveraging advanced machine intelligence techniques, specifically computer vision, to enhance semantic understanding, learning representations, visual recognition, and geospatial data interpretation.