Overview
The Problem with Faithful Explanations
Language models excel at NLU yet fail to produce faithful explanations—ones that causally reflect the model's decision process. Standard fine-tuning is agnostic to how a model allocates probability mass, leading to a structural gap between accuracy and explanation quality.
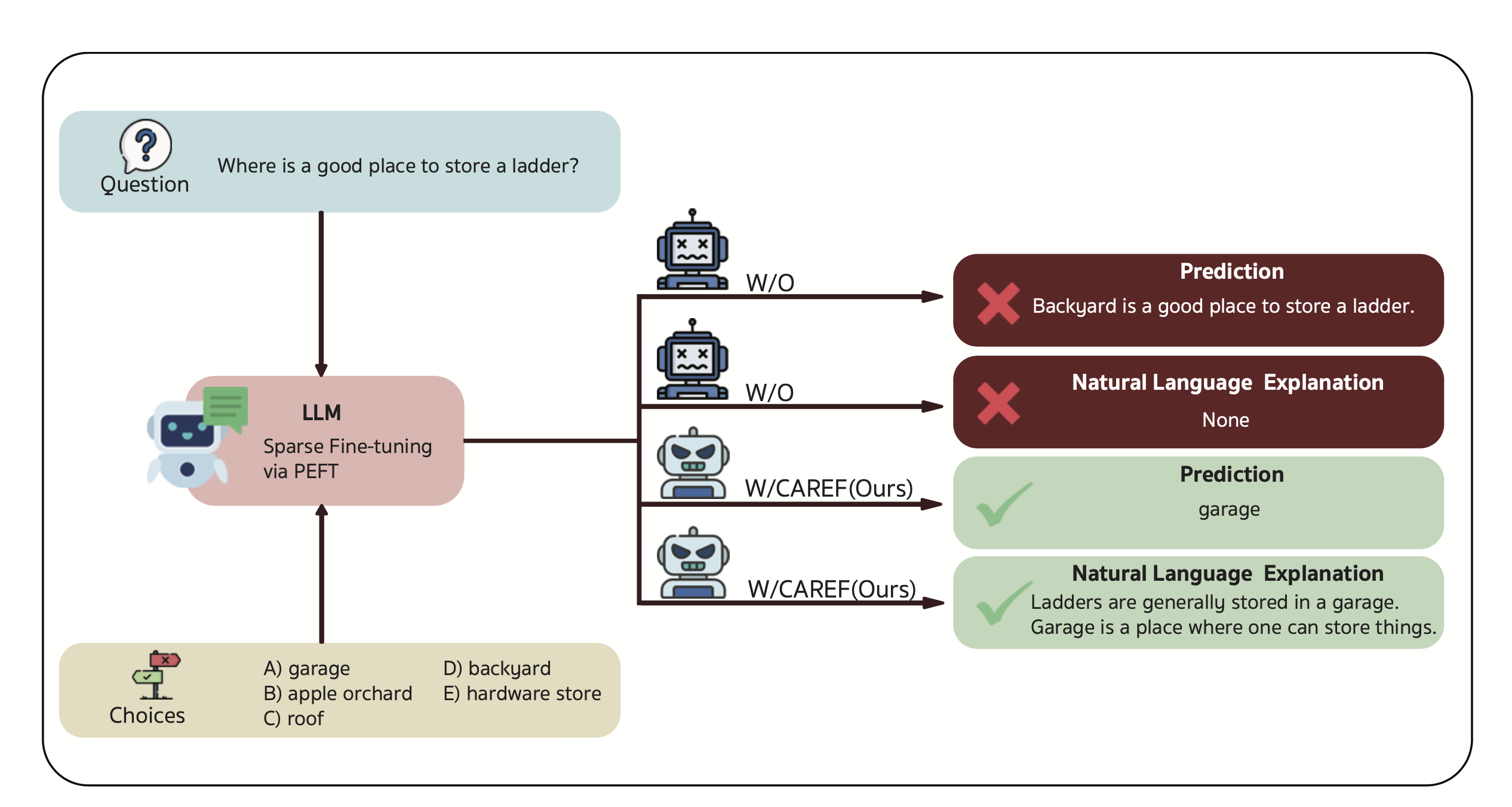
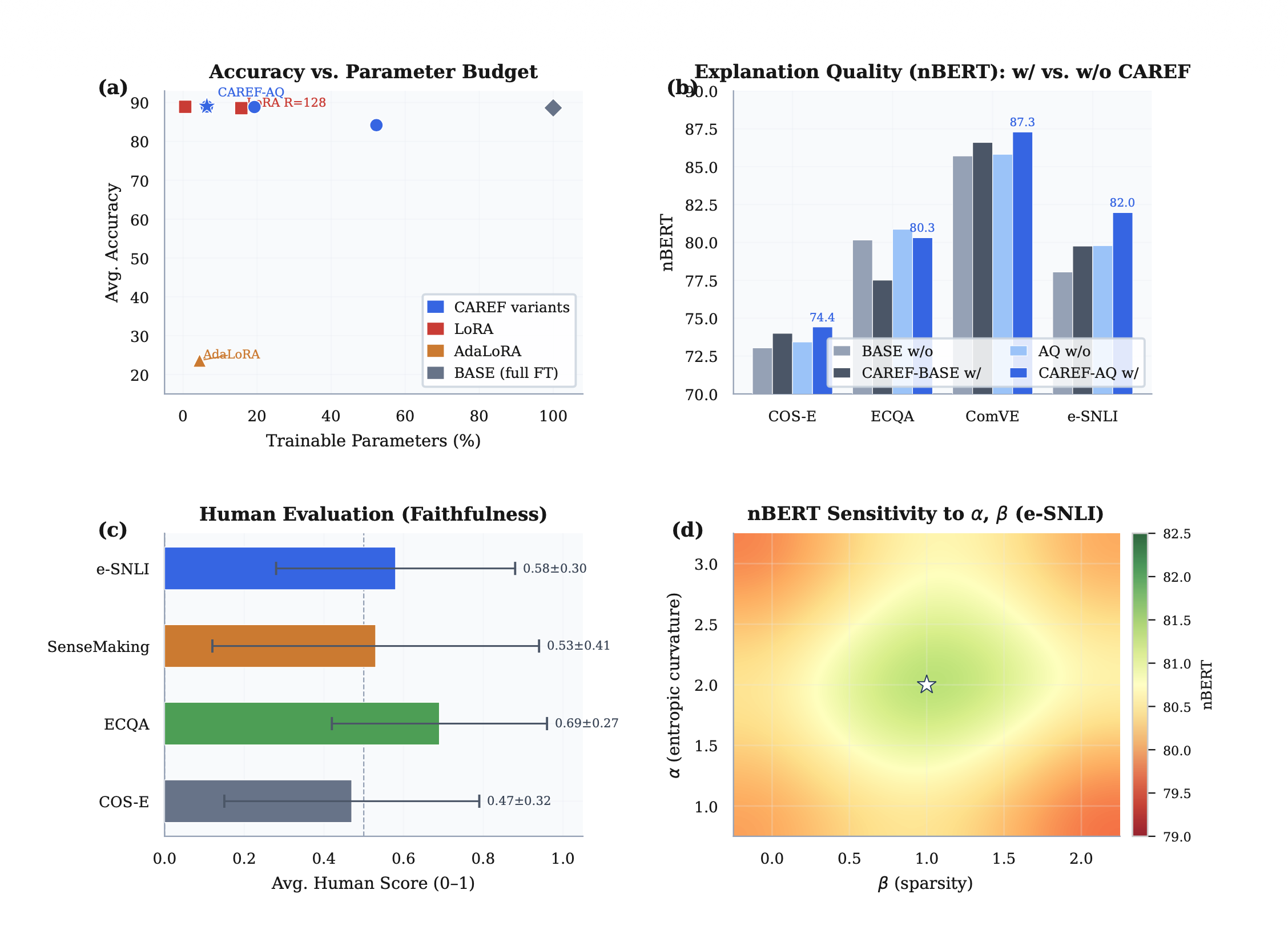
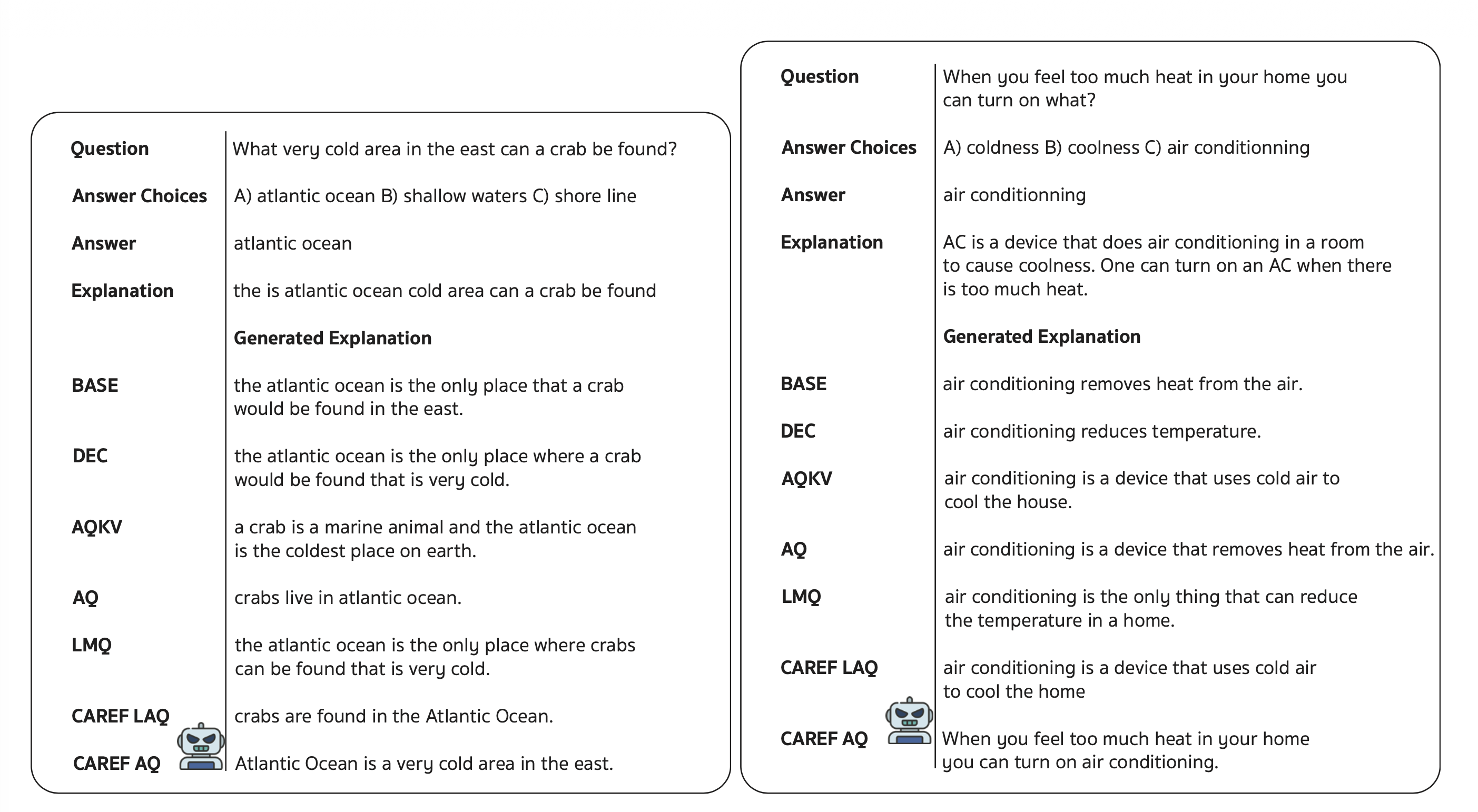
Figure 1. CAREF at a glance: (a) Accuracy vs. trainable parameter budget across variants; (b) nBERT explanation quality per dataset (w/ vs. w/o CAREF); (c) Human evaluation faithfulness scores; (d) Sensitivity of nBERT to α and β on e-SNLI.
❌ Existing Approaches Fail Because…
- • Rationale-supervised methods require expensive token-level annotations
- • Post-hoc attribution (attention rollout, IG) operates after training—cannot influence representations
- • Entropy penalties flatten distributions indiscriminately, harming interpretability
- • Label smoothing redistributes mass uniformly, actively hurting explanation coherence
- • Sparsemax/Entmax introduces hard sparsity with discontinuous gradients
✅ CAREF's Key Insight
- • Single unified loss ℒSCED jointly regulates entropy and sparsity
- • No rationale supervision—only task labels required
- • Fully differentiable, plug-in compatible with any PEFT method
- • Token-adaptive: penalty concentrates on decision-relevant vocabulary
- • Architecture-agnostic: works with T5, BART, LLaMA, GPT families