KST 2026 · Accepted Paper
Seeing Isn't Always Believing:
Evaluating Grad-CAM Faithfulness
in Lung Cancer CT Classification
A rigorous, quantitative evaluation of Grad-CAM faithfulness and localization reliability across modern deep learning architectures.
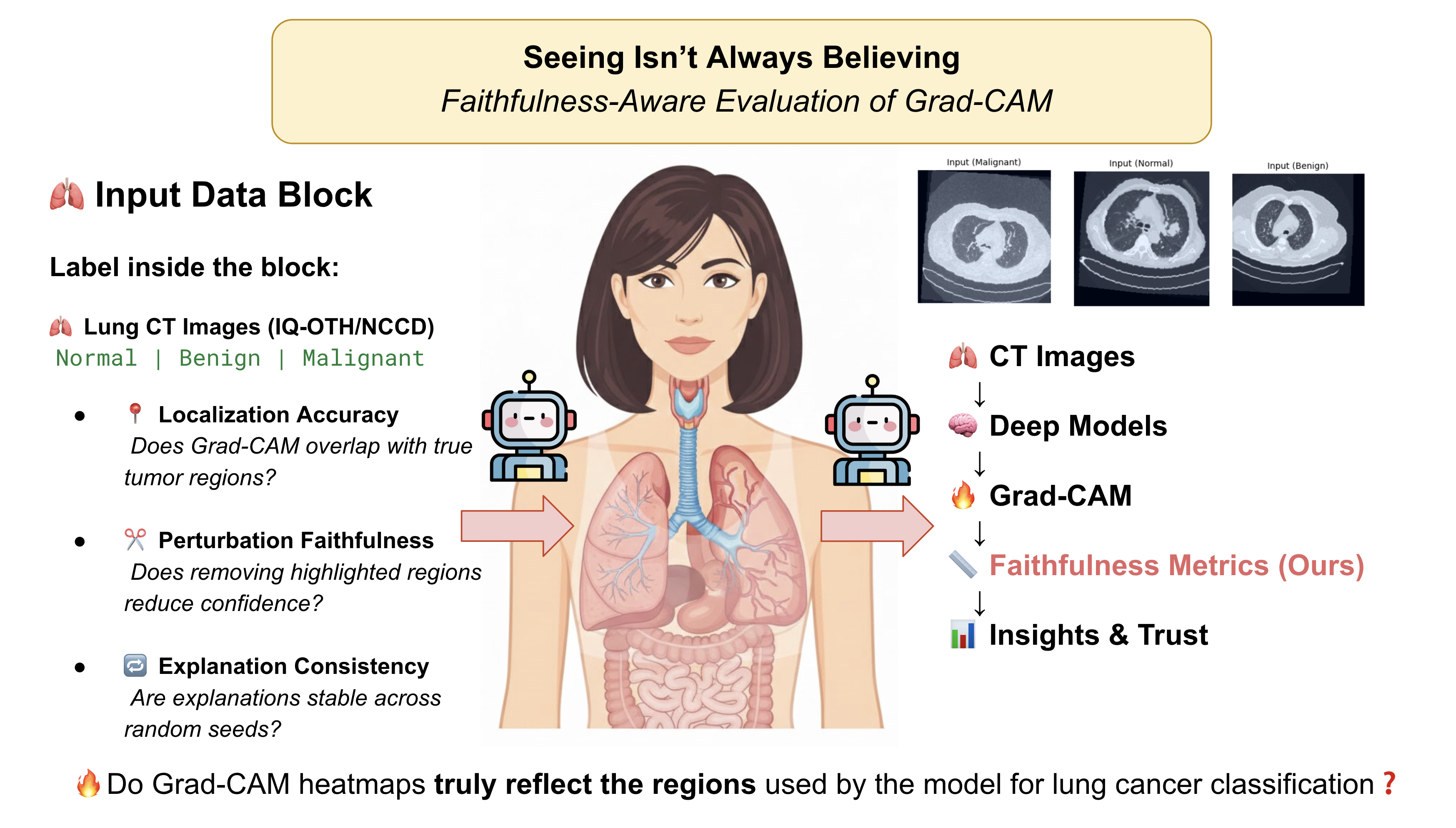
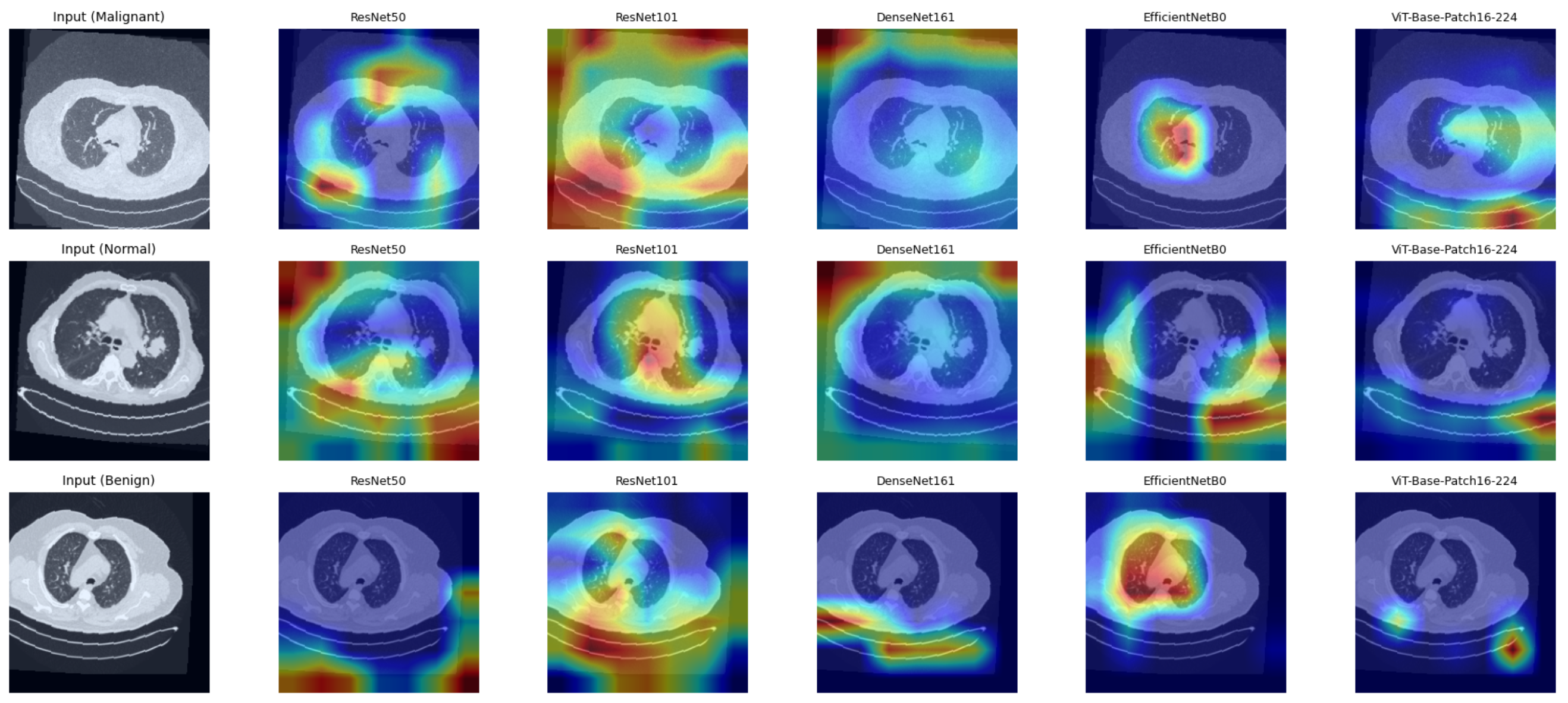
Fig. 1 — Grad-CAM activation maps across CNN and Vision Transformer architectures on lung CT scans.