2
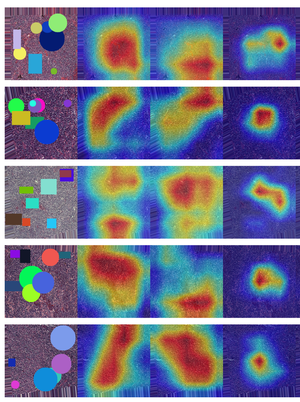

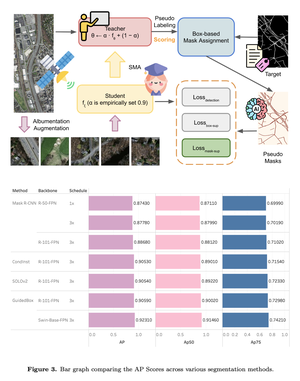
Road segmentation in remote sensing is crucial for applications like urban planning, traffic monitoring, and autonomous driving. Labeling objects via pixel-wise segmentation is challenging compared to bounding boxes. Existing weakly supervised segmentation methods often rely on heuristic bounding box priors, but we propose that box-supervised techniques can yield better results. Introducing GuidedBox, an end-to-end framework for weakly supervised instance segmentation. GuidedBox uses a teacher model to generate high-quality pseudo-masks and employs a confidence scoring mechanism to filter out noisy masks. We also introduce a noise-aware pixel loss and affinity loss to optimize the student model with pseudo-masks. Our extensive experiments show that GuidedBox outperforms state-of-the-art methods like SOLOv2, CondInst, and Mask R-CNN on the Massachusetts Roads Dataset, achieving an AP50 score of 0.9231. It also shows strong performance on SpaceNet and DeepGlobe datasets, proving its versatility in remote sensing applications. Code has been made available at https://github.com/kaopanboonyuen/GuidedBox.
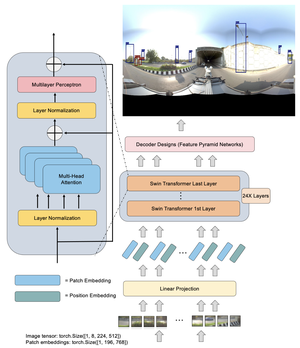
Satellite image inpainting is a critical task in remote sensing, requiring accurate restoration of missing or occluded regions for reliable image analysis. In this paper, we present SatDiff, an advanced inpainting framework based on diffusion models, specifically designed to tackle the challenges posed by very high-resolution (VHR) satellite datasets such as DeepGlobe and the Massachusetts Roads Dataset. Building on insights from our previous work, SatInPaint, we enhance the approach to achieve even higher recall and overall performance. SatDiff introduces a novel Latent Space Conditioning technique that leverages a compact latent space for efficient and precise inpainting. Additionally, we integrate Explicit Propagation into the diffusion process, enabling forward-backward fusion for improved stability and accuracy. Inspired by encoder-decoder architectures like the Segment Anything Model (SAM), SatDiff is seamlessly adaptable to diverse satellite imagery scenarios. By balancing the efficiency of preconditioned models with the flexibility of postconditioned approaches, SatDiff establishes a new benchmark in VHR satellite datasets, offering a scalable and high-performance solution for satellite image restoration. The code for SatDiff is publicly available at https://github.com/kaopanboonyuen/SatDiff.

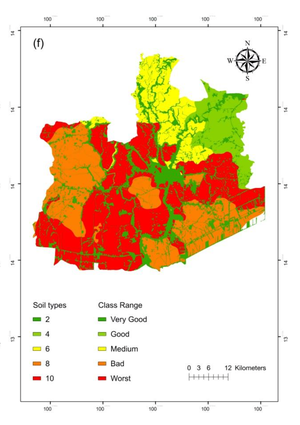
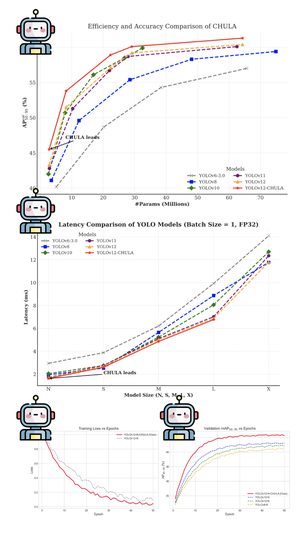
Accurately segmenting land boundaries from Thai land title deeds is crucial for reliable land management and legal processes, but remains challenging due to low-quality scans, diverse layouts, and complex overlapping elements in documents. Existing methods often struggle with these difficulties, resulting in imprecise delineations that can cause disputes or inefficiencies. To address these issues, we propose CHULA, a novel Custom Heuristic Uncertainty-guided Loss tailored specifically for robust land title deed segmentation. CHULA uniquely combines domain-specific heuristic priors with uncertainty modeling in a unified loss function that effectively guides the model to focus on clearer regions while refining boundaries and suppressing noisy areas. Evaluated on a carefully curated Thai Land Title Deed Dataset, CHULA achieves an impressive 92.4% accuracy, significantly surpassing standard segmentation baselines. Our results highlight the promise of integrating uncertainty and heuristic knowledge to enhance segmentation accuracy in complex, real-world documents. The code is publicly available at https://github.com/kaopanboonyuen/CHULA.
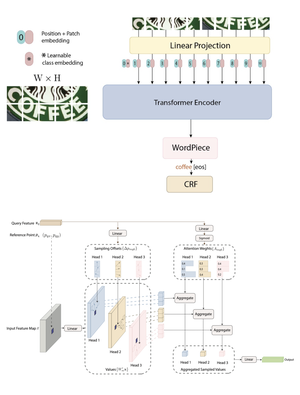
In this paper, we present a novel end-to-end framework that integrates ResNet and Vision Transformer (ViT) backbones with cutting-edge techniques such as Deformable Convolutions, Retrieval-Augmented Generation, and Conditional Random Fields (CRF). These innovations work together to significantly improve feature representation and Optical Character Recognition (OCR) performance. By replacing the standard convolution layers in the third and fourth blocks with Deformable Convolutions, the framework adapts more flexibly to complex text layouts, while adaptive dropout helps prevent overfitting and enhance generalization. Moreover, incorporating CRFs refines the sequence modeling for more accurate text recognition. Extensive experiments on six benchmark datasets—IC13, IC15, SVT, IIIT5K, SVTP, and CUTE80—demonstrate the framework’s exceptional performance. Our method represents a significant leap forward in OCR technology, addressing challenges in recognizing text with various distortions, fonts, and orientations. The framework has proven not only effective in controlled conditions but also adaptable to more complex, real-world scenarios. The code for this framework is available at https://github.com/kaopanboonyuen/DOTA.