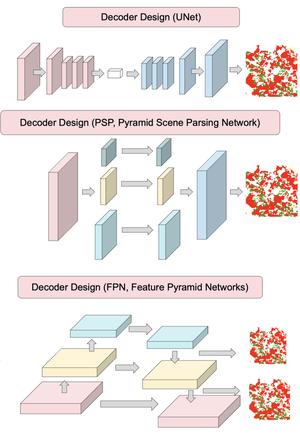
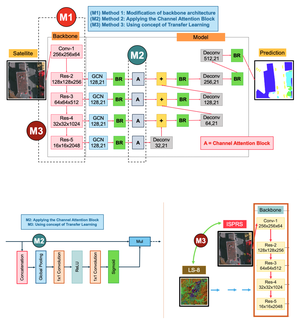
In the remote sensing domain, it is crucial to complete semantic segmentation on the raster images, e.g., river, building, forest, etc., on raster images. A deep convolutional encoder–decoder (DCED) network is the state-of-the-art semantic segmentation method for remotely sensed images. However, the accuracy is still limited, since the network is not designed for remotely sensed images and the training data in this domain is deficient. In this paper, we aim to propose a novel CNN for semantic segmentation particularly for remote sensing corpora with three main contributions. First, we propose applying a recent CNN called a global convolutional network (GCN), since it can capture different resolutions by extracting multi-scale features from different stages of the network. Additionally, we further enhance the network by improving its backbone using larger numbers of layers, which is suitable for medium resolution remotely sensed images. Second, “channel attention” is presented in our network in order to select the most discriminative filters (features). Third, “domain-specific transfer learning” is introduced to alleviate the scarcity issue by utilizing other remotely sensed corpora with different resolutions as pre-trained data. The experiment was then conducted on two given datasets (i) medium resolution data collected from Landsat-8 satellite and (ii) very high resolution data called the ISPRS Vaihingen Challenge Dataset. The results show that our networks outperformed DCED in terms of 𝐹1 for 17.48% and 2.49% on medium and very high resolution corpora, respectively.