Transformer-Based Decoder Designs for Semantic Segmentation on Remotely Sensed Images
Abstract
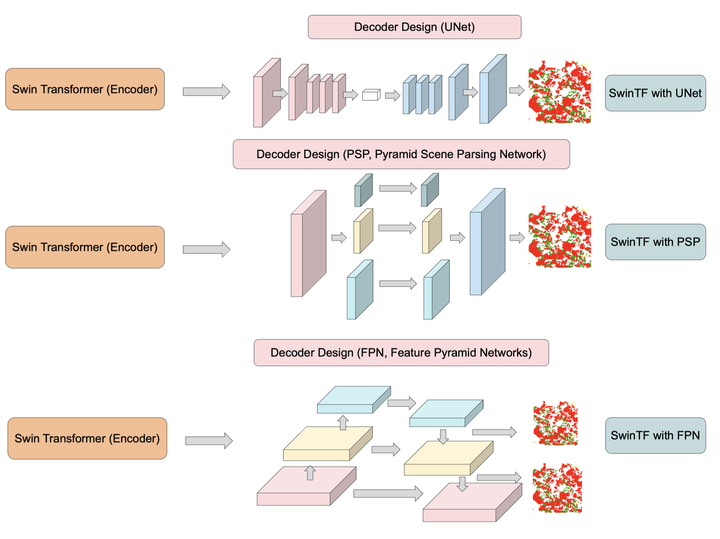
Transformers have demonstrated remarkable accomplishments in several natural language processing (NLP) tasks as well as image processing tasks. Herein, we present a deep-learning (DL) model that is capable of improving the semantic segmentation network in two ways. First, utilizing the pre-training Swin Transformer (SwinTF) under Vision Transformer (ViT) as a backbone, the model weights downstream tasks by joining task layers upon the pretrained encoder. Secondly, decoder designs are applied to our DL network with three decoder designs, U-Net, pyramid scene parsing (PSP) network, and feature pyramid network (FPN), to perform pixel-level segmentation. The results are compared with other image labeling state of the art (SOTA) methods, such as global convolutional network (GCN) and ViT. Extensive experiments show that our Swin Transformer (SwinTF) with decoder designs reached a new state of the art on the Thailand Isan Landsat-8 corpus (89.8% 𝐹1 score), Thailand North Landsat-8 corpus (63.12% 𝐹1 score), and competitive results on ISPRS Vaihingen. Moreover, both our best-proposed methods (SwinTF-PSP and SwinTF-FPN) even outperformed SwinTF with supervised pre-training ViT on the ImageNet-1K in the Thailand, Landsat-8, and ISPRS Vaihingen corpora.
Teerapong Panboonyuen
My research focuses on leveraging advanced machine intelligence techniques, specifically computer vision, to enhance semantic understanding, learning representations, visual recognition, and geospatial data interpretation.