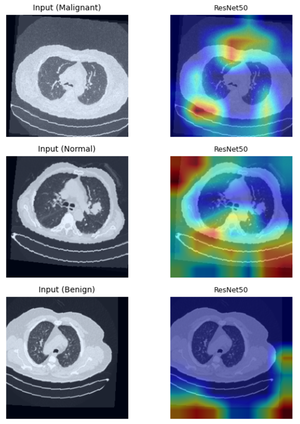
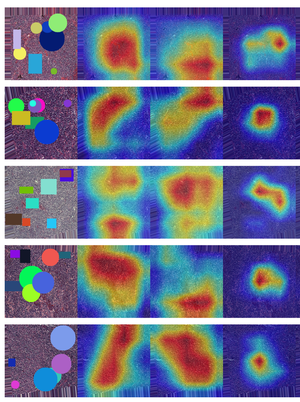
This study provides a rigorous and model-aware examination of the faithfulness and spatial reliability of Grad-CAM explanations for lung cancer CT image classification across both convolutional neural networks and Vision Transformer architectures. By systematically analyzing localization accuracy, perturbation-based faithfulness, and explanation consistency, the work reveals pronounced architecture-dependent disparities in how visual explanations align with true diagnostic evidence. While Grad-CAM often produces visually convincing heatmaps for convolutional models, these explanations can be spatially coarse or influenced by spurious correlations, raising concerns about shortcut learning and misleading interpretability. More critically, the analysis demonstrates that transformer-based models, despite strong predictive performance, exhibit a marked degradation in Grad-CAM reliability due to non-local attention mechanisms. Together, these findings underscore a central message, visually appealing explanations do not necessarily imply faithful model reasoning. The work highlights fundamental limitations of saliency-based XAI methods in high-stakes medical imaging and calls for more principled, model-aware interpretability approaches that can support genuinely trustworthy and clinically meaningful AI systems.