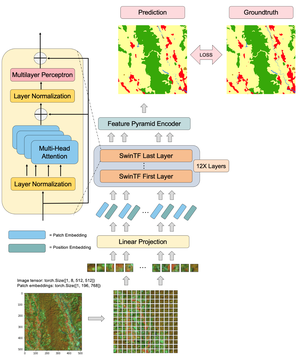
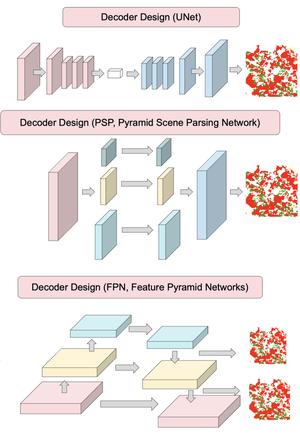
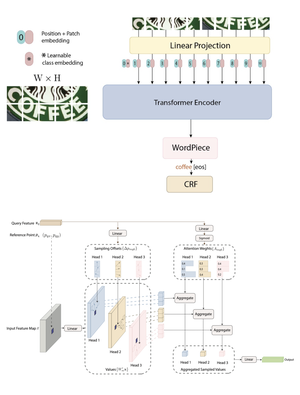
Vision Transformer
In this paper, we present a novel end-to-end framework that integrates ResNet and Vision Transformer (ViT) backbones with cutting-edge techniques such as Deformable Convolutions, Retrieval-Augmented Generation, and Conditional Random Fields (CRF). These innovations work together to significantly improve feature representation and Optical Character Recognition (OCR) performance. By replacing the standard convolution layers in the third and fourth blocks with Deformable Convolutions, the framework adapts more flexibly to complex text layouts, while adaptive dropout helps prevent overfitting and enhance generalization. Moreover, incorporating CRFs refines the sequence modeling for more accurate text recognition. Extensive experiments on six benchmark datasets—IC13, IC15, SVT, IIIT5K, SVTP, and CUTE80—demonstrate the framework’s exceptional performance. Our method represents a significant leap forward in OCR technology, addressing challenges in recognizing text with various distortions, fonts, and orientations. The framework has proven not only effective in controlled conditions but also adaptable to more complex, real-world scenarios. The code for this framework is available at https://github.com/kaopanboonyuen/DOTA.
Forecasting sea surface currents is essential for applications such as maritime navigation, environmental monitoring, and climate analysis, particularly in regions like the Gulf of Thailand and the Andaman Sea. This paper introduces SEA-ViT, an advanced deep learning model that integrates Vision Transformer (ViT) with bidirectional Gated Recurrent Units (GRUs) to capture spatio-temporal covariance for predicting sea surface currents (U, V) using high-frequency radar (HF) data. The name SEA-ViT is derived from Sea Surface Currents Forecasting using Vision Transformer, highlighting the model’s emphasis on ocean dynamics and its use of the ViT architecture to enhance forecasting capabilities. SEA-ViT is designed to unravel complex dependencies by leveraging a rich dataset spanning over 30 years and incorporating ENSO indices (El Niño, La Niña, and neutral phases) to address the intricate relationship between geographic coordinates and climatic variations. This development enhances the predictive capabilities for sea surface currents, supporting the efforts of the Geo-Informatics and Space Technology Development Agency (GISTDA) in Thailand’s maritime regions. The code and pretrained models are available at https://github.com/kaopanboonyuen/gistda-ai-sea-surface-currents.