Optical Character Recognition
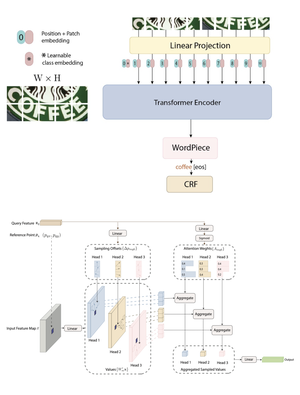
In this paper, we present a novel end-to-end framework that integrates ResNet and Vision Transformer (ViT) backbones with cutting-edge techniques such as Deformable Convolutions, Retrieval-Augmented Generation, and Conditional Random Fields (CRF). These innovations work together to significantly improve feature representation and Optical Character Recognition (OCR) performance. By replacing the standard convolution layers in the third and fourth blocks with Deformable Convolutions, the framework adapts more flexibly to complex text layouts, while adaptive dropout helps prevent overfitting and enhance generalization. Moreover, incorporating CRFs refines the sequence modeling for more accurate text recognition. Extensive experiments on six benchmark datasets—IC13, IC15, SVT, IIIT5K, SVTP, and CUTE80—demonstrate the framework’s exceptional performance. Our method represents a significant leap forward in OCR technology, addressing challenges in recognizing text with various distortions, fonts, and orientations. The framework has proven not only effective in controlled conditions but also adaptable to more complex, real-world scenarios. The code for this framework is available at https://github.com/kaopanboonyuen/DOTA.