Object Detection of Road Assets Using Transformer-Based YOLOX with Feature Pyramid Decoder on Thai Highway Panorama
Abstract
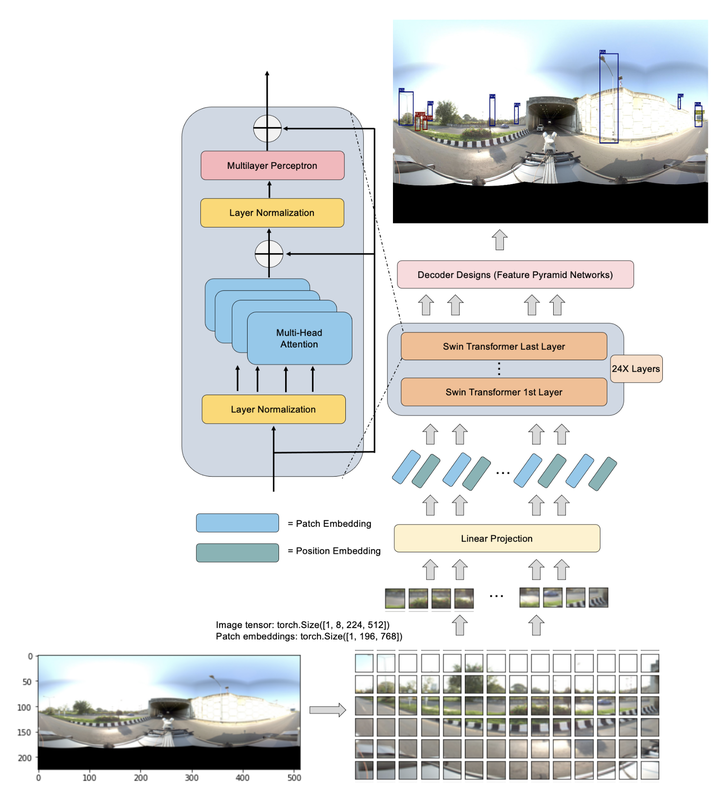
Detecting objects of varying sizes, like kilometer stones, remains a significant challenge and directly affects the accuracy of object counts. Transformers have shown remarkable success in natural language processing (NLP) and image processing due to their ability to model long-range dependencies. This paper proposes an enhanced YOLO (You Only Look Once) series with two key contributions, (i) We employ a pre-training objective to obtain original visual tokens from image patches of road assets, using a pre-trained Vision Transformer (ViT) backbone, which is then fine-tuned on downstream tasks with additional task layers. (ii) We incorporate Feature Pyramid Network (FPN) decoder designs into our deep learning network to learn the significance of different input features, avoiding issues like feature mismatch and performance degradation that arise from simple summation or concatenation. Our proposed method, Transformer-Based YOLOX with FPN, effectively learns general representations of objects and significantly outperforms state-of-the-art detectors, including YOLOv5S, YOLOv5M, and YOLOv5L. It achieves a 61.5% AP on the Thailand highway corpus, surpassing the current best practice (YOLOv5L) by 2.56% AP on the test-dev dataset.
Teerapong Panboonyuen
My research focuses on leveraging advanced machine intelligence techniques, specifically computer vision, to enhance semantic understanding, learning representations, visual recognition, and geospatial data interpretation.